

Get full control over your infrastructure and save up to 75% on cloud bills with Uniskai!
Try For FreeMicroservices Vocabulary: Teams Organization, User Interface, Data Storing
The microservices’ terminology is quite rich, so we’re going step by step to show you how the main elements work. Today, we discuss the terms associated with the microservices’ concepts of built for business, designed for failure, and decentralized data management.
1. Teams Organization
As we explored in previous articles, microservices focus on particular business capabilities and priorities. It’s about having logic everywhere, including a team organization pattern. In most cases, the managers responsible for microservices-based projects deal with a broad tech stack and a lot of external collaboration. This results in having the cross-functional engineering teams, capable of developing user interfaces, databases, and backend parts. Such teams build specific individual services that communicate with each other and own the product for its lifetime.
So, if you choose to utilize the microservices architecture, be aware that it directly affects the way you’d have to organize the project team. As microservices style splits your app’s main domain into separate subdomains, you’ll be assembling not one big team per primary domain but several teams of various sizes per each subdomain.
Yes, the teams for microservices projects are perfectly scalable and right-sized. Based on the tech requirements of each subdomain, you can set up smaller or bigger development units. Of course, the bigger business functionality a subdomain covers, the bigger-sized team you need. The main advantage of this approach is that the teams are totally independent and solely responsible only for the product they build, but entirely from development to deployment, sure.
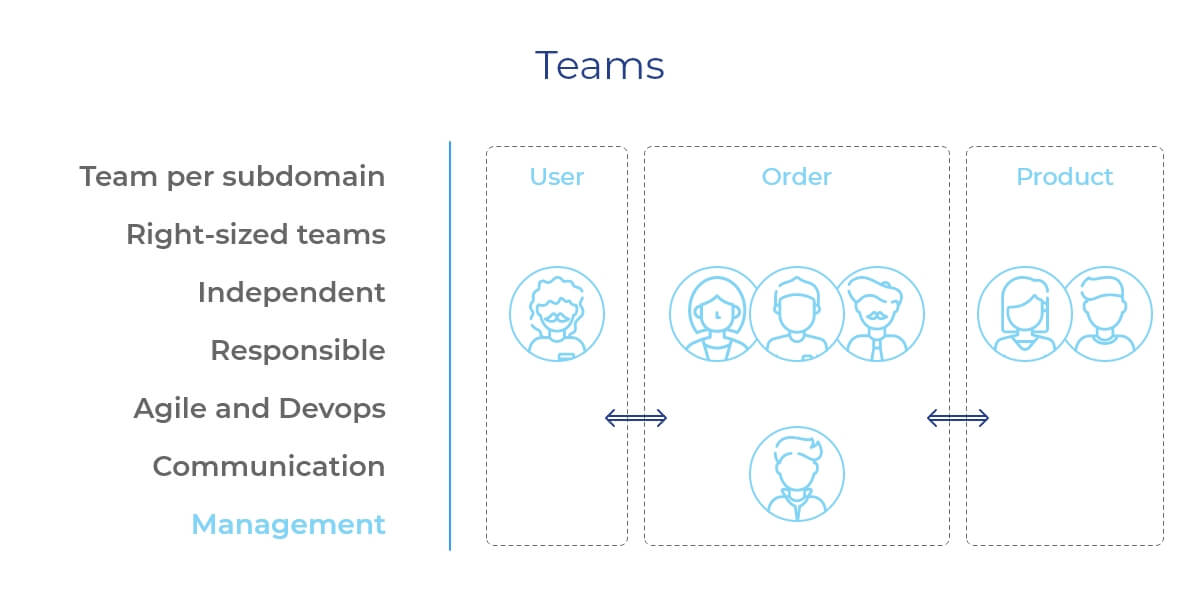
That’s why most such projects operate based on Agile and DevOps practices that empower different engineering teams to operate on the maximum productivity within their skill sets. At the same time, these separate teams work closely together in perfect synch, building parts of the same final product that are going to be integrated with each other when the day comes. For sure, having a few cross-functional teams that own each microservice independently requires a deep trust.
So, it’s in your best interest to carefully manage such an organizational structure to ensure that all teams follow a clear version control policy for their code and tech docs, which can be stored in different repositories. Use a version control software (Git, Subversion, etc.) that helps to track each version of the microservices being developed. Keep in mind that one subdomain team can be still working on the 3.3.3 version of their service, while another team can already be testing some far later version of the whole product.
2. User Interface (UI)
And this one is about design for failure, yes. The microservices are independent components, so you have to design your app in a way to tolerate the failure of any separate service. Sure, regular monitoring of the microservices ecosystem helps to prevent crashes. But still, the services can let you down due to a number of reasons, and your app must respond to the emergency as seamlessly as possible and cope with failure appropriately.
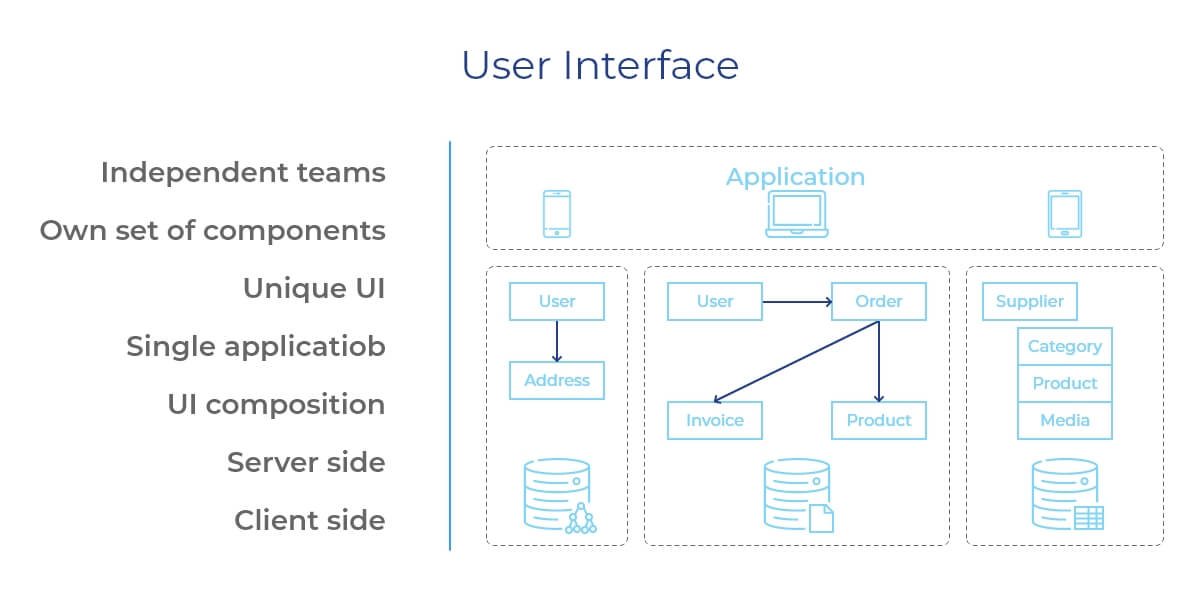
Not every microservice project has a UI development phase, but when it happens, you should follow a proven technique to aggregate them. Your isolated teams can build and maintain their own set of graphical components, integrate them, and work closely with the designers to create the best user experience for the release version of your app. But how to implement a UI that displays information sent by the combination of multiple microservices?
You have to create a UI mixture using one of the two available design patterns. Here you can choose the server-side page composition to build web pages on the backend by combining HTML elements developed by different teams. Or you can go through the client-side approach, where your browser will form a single interface by composing all UI fragments from multiple teams. In both cases, you have to set up a team able to build the responsive app’s ecosystem that will aggregate multiple UI parts.
3. Data Storing
The good old centralized governance and management don’t work for microservices since this style uses a variety of technologies, tools, and platforms. You can’t manage it all using the centralized approach. Every microservices-based project follows the principles of decentralized data management.
What does it mean? The monolithic software uses a single database for persistent data, while microservices-based apps decentralize their data storing utilizing the Polyglot Persistence concept. Simply put, in microservices software development, each service has its own independent database.
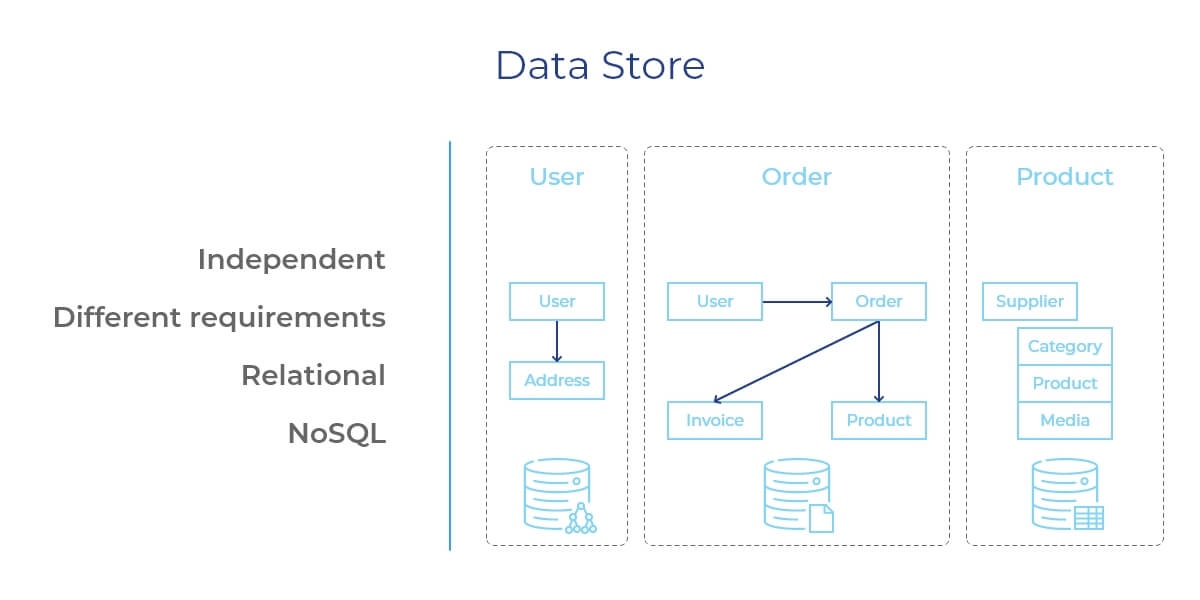
This approach might result in some degree of data duplication and consistency maintenance issues, but there is no other way. The necessity is related to the Domain-Driven Design and Bounded Context. This approach divides each big business domain up into multiple bounded contexts outlining the relationships and connections between them. The correlation between the services and bounded contexts is clear and easy-to-navigate, even considering the separations.
To keep being loosely-coupled, independently developed, deployed, and scaled, the microservices have to manage their data via independent data storages with corresponding tech requirements. Considering the specifics of your app, one database can be responsible only for reading and processing the information, the other one will be sending the replies, and the third one will handle only the transactions. This way, if one of your teams implements changes in one service’s database, it won’t affect any other app’s services. The database for each service can be of any type depending on the project you develop.
Afterword
If you have questions on any of the discussed elements, please, don’t hesitate to send us a message. We’re always ready to provide you with a free consultation. Also, stay tuned for our next articles, we’re going to explore the specifics of the distributed microservices, their scalability, security issues, and much more.


